Latency, throughput, and cost show whether hiring systems can carry load
TalentAI is not only about matching. Candidate-library scale, P50 / P95 / P99, successful matches per minute, and cost per successful task belong in the case scope.
This case shows how a hiring intelligence system moves from demo to measurable delivery: the public workflow proves usability, estimates give target ranges, benchmarks verify P50 / P95 / QPS / cost, and evaluation verifies Recall@K, evidence coverage, and regression risk.
TalentAI is not only about matching. Candidate-library scale, P50 / P95 / P99, successful matches per minute, and cost per successful task belong in the case scope.
A hiring intelligence system cannot return scores alone. It must show expert-approved candidates are recalled, ranked, and explained with resume evidence.
The public demo shows the workflow, engineering estimates give target ranges, controlled benchmarks verify numbers, and production SLA is calibrated in the client environment.
The website can state engineering estimates and target baselines when assumptions, data scale, concurrency, and verification paths are explicit. The deliverable is making those numbers real, measured, and monitored.
Talent pool, JD matching, resume parsing, and evidence explanation are real surfaces for walkthroughs.
Target ranges are based on dataset size, concurrency, model routing, cache, and retry assumptions.
Fixed data, environment, version, and raw logs verify latency, throughput, failure rate, and unit cost.
Gold sets and regression sets verify recall, ranking, evidence coverage, and degradation risk.
Hiring matching should not ask a model to guess fit from nothing. Candidate recall must be accurate, ranking stable, and evidence explicit before generation or explanation happens.
Role requirements are split into hard filters, skill entities, experience semantics, industry background, and risk signals before entering structured filters, full-text search, and vector recall.
Chinese skill terms are covered by zhparser and full-text indexes, profile fields are filtered in PostgreSQL, and experience/project descriptions use pgvector HNSW for semantic recall.
Keyword, field, and vector recall each have bias. RRF fuses rankings first, then the LLM Gateway reranks, scores, and explains role fit by dimension.
The output is not just similarity. It returns candidates, matched fields, resume evidence, risk points, and scoring rationale for recruiter review.
PDF, Word, and text resumes become raw records plus experience, skills, education, companies, and project context.
Job descriptions are split into hard filters, soft preferences, skill entities, experience semantics, and negative risk signals.
PostgreSQL, zhparser, and pgvector HNSW recall candidates in parallel, then RRF merges rankings.
The LLM Gateway scores only over retrieved evidence while permissions, logs, backups, and recovery stay in a controlled client environment.
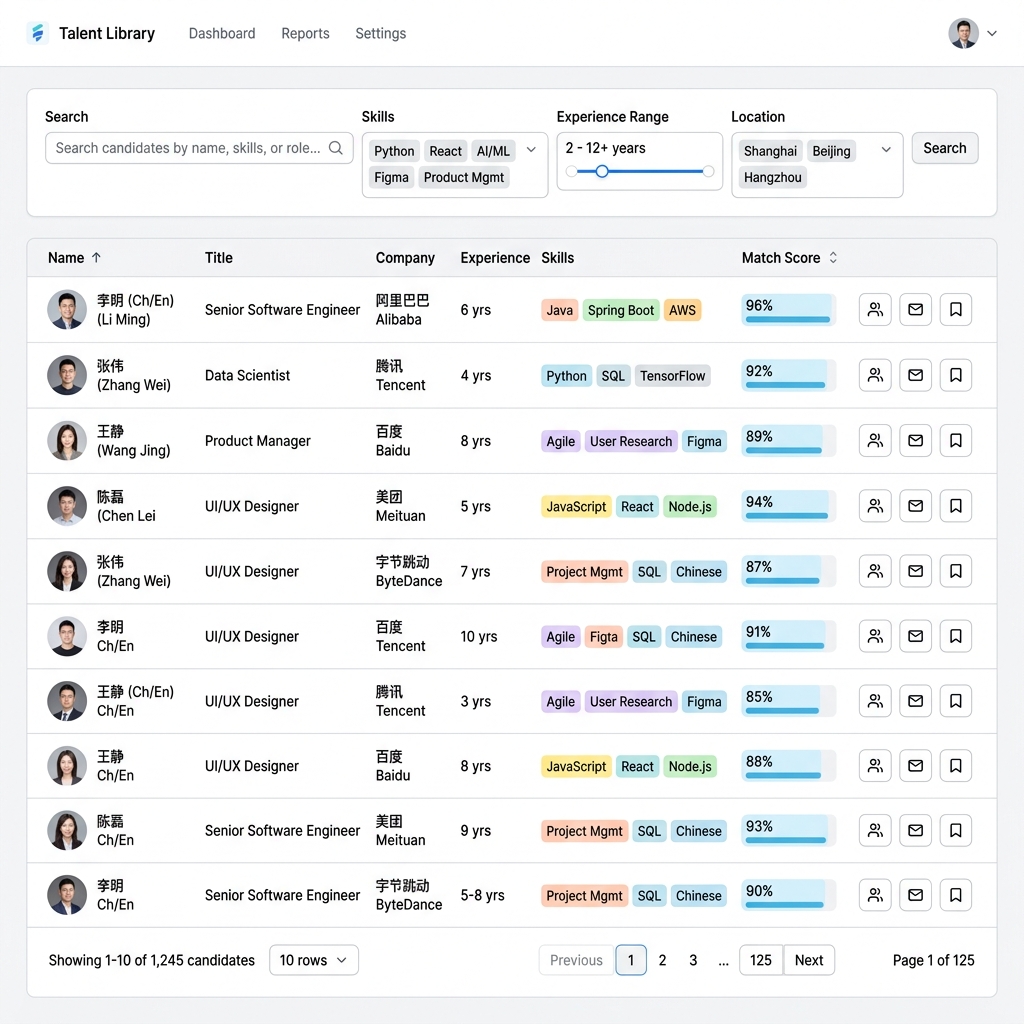
Scan candidates by skills, company, tenure, and match quality.
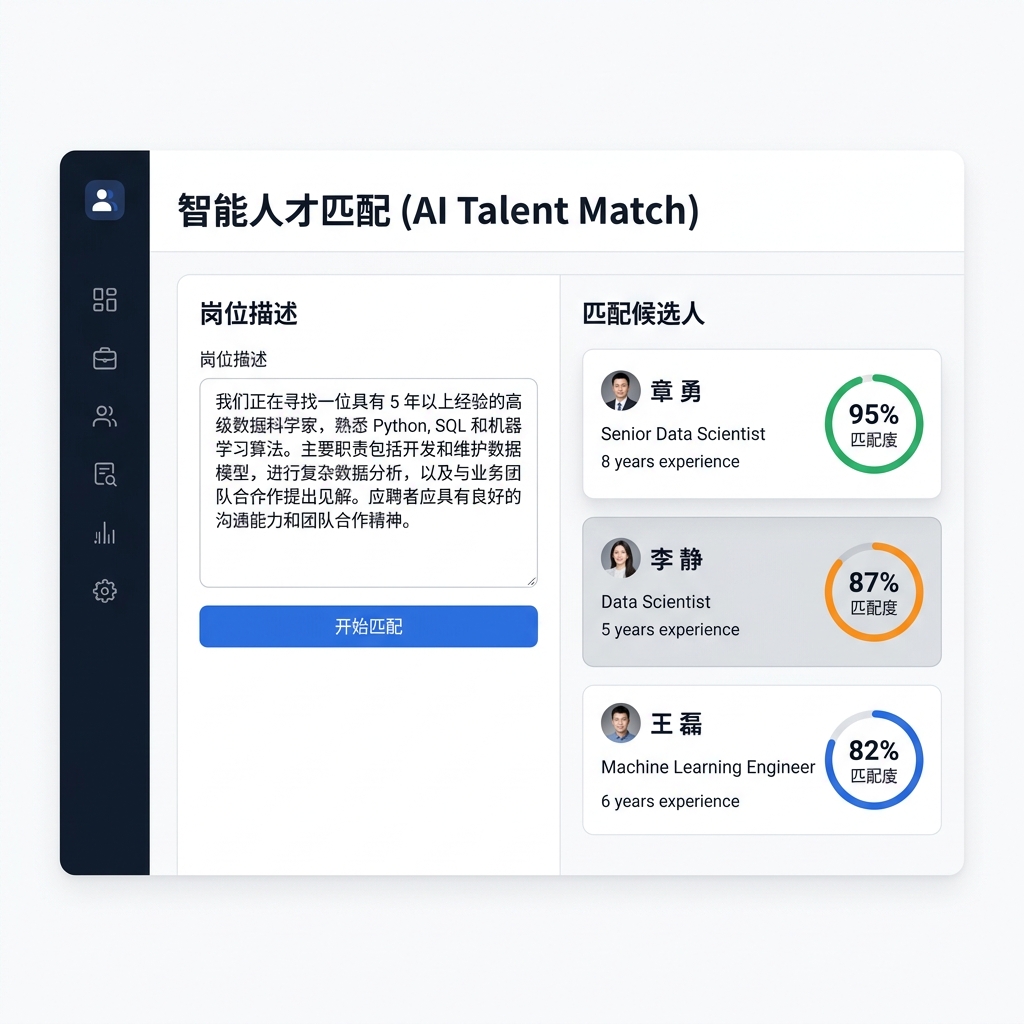
Role requirements, candidate scores, and explanations live in one decision surface.
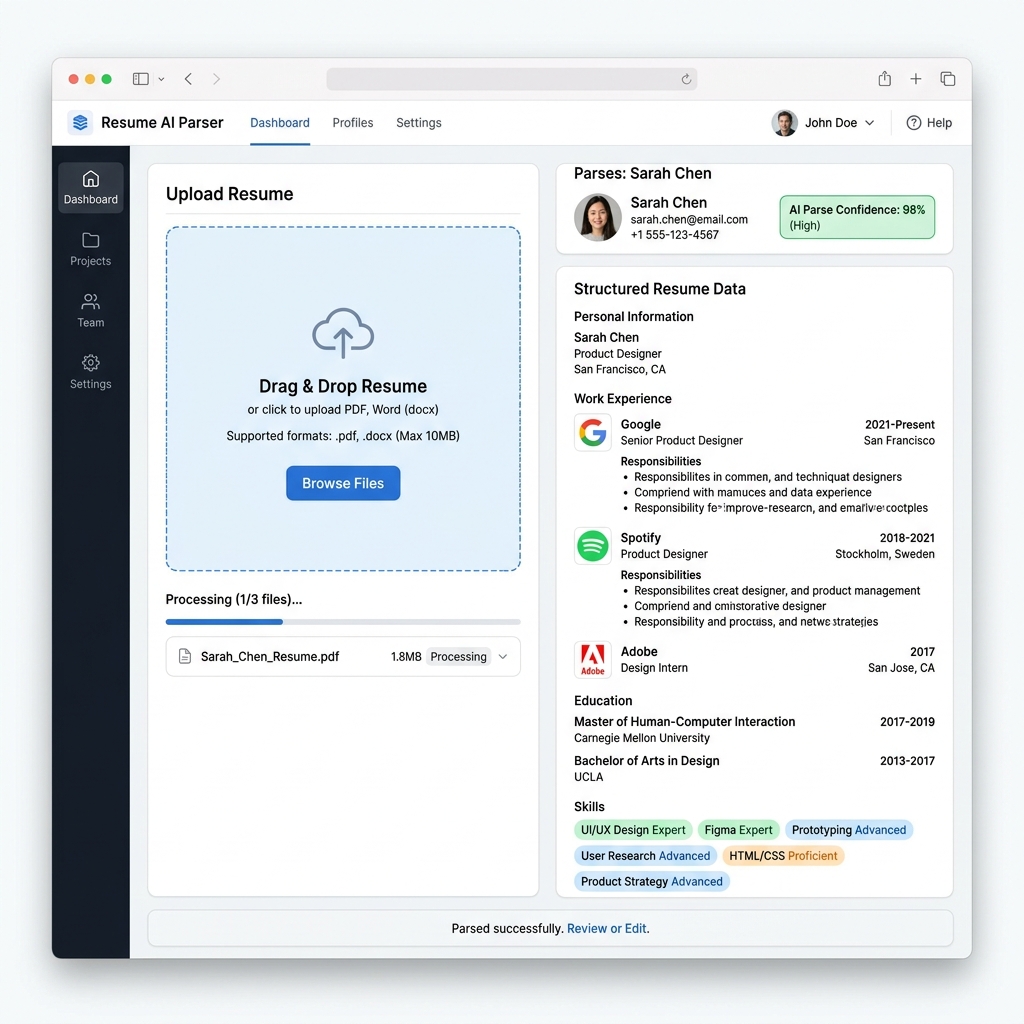
Uploads become structured experience and skill tags with less manual entry.
The method is to translate business complexity into latency, throughput, success rate, unit cost, recall quality, and human intervention rate, then decide retrieval, scheduling, model routing, evaluation, and private operations boundaries.